Deploy fine-tuned LLMs without compromising on control
“Our ML engineers want to use Modal for everything. Modal helped reduce our VLM document parsing latency by 3x and allowed us to scale throughput to >100,000 pages per minute.”
“Modal lets us deploy new ML models in hours rather than weeks. We use it across spam detection, recommendations, audio transcription, and video pipelines, and it’s helped us move faster with far less complexity.”
“Modal makes it unbelievably quick to deploy our models onto scalable infrastructure. We’ve been able to move faster on our last few model launches, including Olmo and Tülu, thanks to the platform.”
Ship faster with Python-defined infrastructure
import modalvllm_image = ( modal.Image.from_registry(f"nvidia/{tag}", add_python="3.12") .uv_pip_install("vllm==0.10.2", "torch==2.8.0"))model_cache = modal.Volume.from_name("huggingface-cache", create_if_missing=True)app = modal.App("vllm-inference")@app.function(image=vllm_image, gpu="H100", volumes={"/root/.cache/huggingface": model_cache})@modal.web_server(port=8000)def serve(): import subprocess cmd = "vllm serve Qwen/Qwen3-8B-FP8 --port 8000" subprocess.Popen(cmd)Inference optimizations that you control
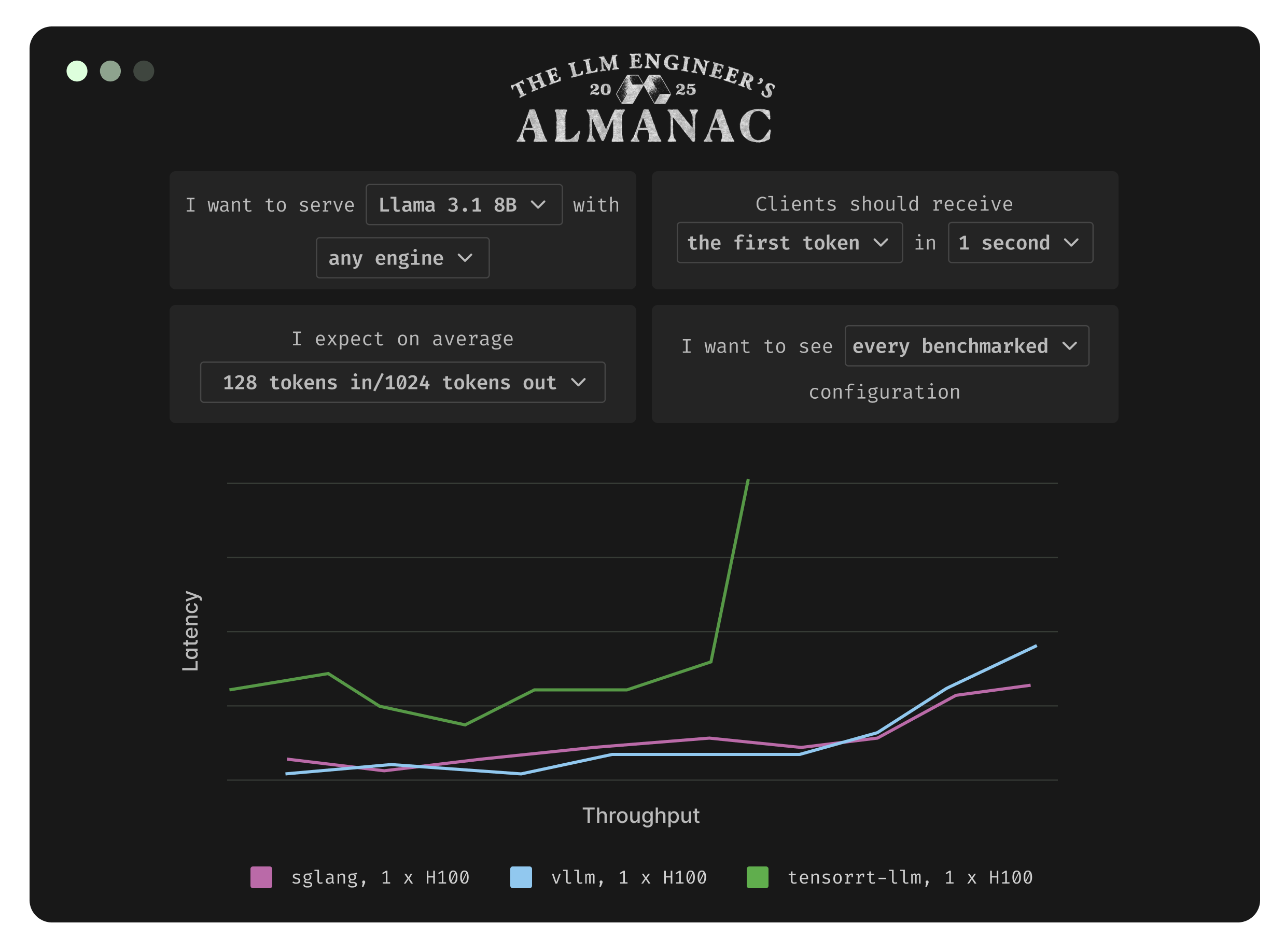
Deploy any state-of-the-art or custom LLM using our flexible Python SDK.
Our in-house ML engineering team helps you implement inference optimizations specific to your workload.
You maintain full control of all code and deployments for instant iterations. No black boxes.
Autoscale to thousands of GPUs without reservations
Modal’s Rust-based container stack spins up GPUs in < 1s.
Modal autoscales up and down for max cost efficiency.
Modal’s proprietary cloud capacity orchestrator guarantees high GPU availability.

'/%3e%3cpath%20d='M109.623%2064L73.2925%201.07001C72.0925%201.76001%2071.0825%202.76%2070.3625%204L1.0725%20124C-0.3575%20126.48%20-0.3575%20129.52%201.0725%20132L33.4026%20188C34.1126%20189.24%2035.1325%20190.24%2036.3325%20190.93L109.613%2064H109.623Z'%20fill='url(%23paint1_linear_342_139)'/%3e%3cpath%20d='M183.513%2064H109.613L36.3325%20190.93C37.5325%20191.62%2038.9025%20192%2040.3325%20192H104.993C107.853%20192%20110.492%20190.47%20111.922%20188L183.513%2064Z'%20fill='%2309AF58'/%3e%3cpath%20d='M365.963%20132C366.673%20130.76%20367.033%20129.38%20367.033%20128H294.372L258.042%20190.93C259.242%20191.62%20260.612%20192%20262.042%20192H326.703C329.563%20192%20332.202%20190.47%20333.632%20188L365.963%20132Z'%20fill='%2309AF58'/%3e%3cpath%20d='M225.083%200C223.653%200%20222.283%200.380007%20221.083%201.07001L294.362%20128H367.023C367.023%20126.62%20366.663%20125.24%20365.953%20124L296.672%204C295.242%201.53%20292.603%200%20289.743%200H225.073H225.083Z'%20fill='url(%23paint2_linear_342_139)'/%3e%3cpath%20d='M258.033%20190.93L294.362%20128L221.083%201.07001C219.883%201.76001%20218.873%202.76%20218.153%204L183.513%2064L255.103%20188C255.813%20189.24%20256.833%20190.24%20258.033%20190.93Z'%20fill='url(%23paint3_linear_342_139)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_342_139'%20x1='155.803'%20y1='80'%20x2='101.003'%20y2='-14.93'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23BFF9B4'/%3e%3cstop%20offset='1'%20stop-color='%2380EE64'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_342_139'%20x1='8.62251'%20y1='174.93'%20x2='100.072'%20y2='16.54'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2380EE64'/%3e%3cstop%20offset='0.18'%20stop-color='%237BEB63'/%3e%3cstop%20offset='0.36'%20stop-color='%236FE562'/%3e%3cstop%20offset='0.55'%20stop-color='%235ADA60'/%3e%3cstop%20offset='0.74'%20stop-color='%233DCA5D'/%3e%3cstop%20offset='0.93'%20stop-color='%2318B759'/%3e%3cstop%20offset='1'%20stop-color='%2309AF58'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint2_linear_342_139'%20x1='340.243'%20y1='143.46'%20x2='248.793'%20y2='-14.93'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23BFF9B4'/%3e%3cstop%20offset='1'%20stop-color='%2380EE64'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint3_linear_342_139'%20x1='284.822'%20y1='175.47'%20x2='193.372'%20y2='17.0701'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2380EE64'/%3e%3cstop%20offset='0.18'%20stop-color='%237BEB63'/%3e%3cstop%20offset='0.36'%20stop-color='%236FE562'/%3e%3cstop%20offset='0.55'%20stop-color='%235ADA60'/%3e%3cstop%20offset='0.74'%20stop-color='%233DCA5D'/%3e%3cstop%20offset='0.93'%20stop-color='%2318B759'/%3e%3cstop%20offset='1'%20stop-color='%2309AF58'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)